Home » Learning Curve » Developers Workshop
Another #EpicFail for Twitter UI CodeTwitter management must do something radical.
The hits just keep on coming. Running an enterprise with several hundred million users in realtime, Twitter keep breaking all the rules for sound programming practices.
Not a word about their backend crew though: there are some marvelous things going on at that site, with an incredible throughput perhaps never before attempted anywhere on the web. That Twitter can even keep up with the flow - the onslaught - is incredible.
So what happens to their daycare crew tasked with coding the UI?
There was a time - that time still exists - when important code changes for important systems were put through rigorous tests in isolated test environments where a single infinitesimal flaw could wreak havoc. Many programmers work in such conditions even today. One must wonder what they think of the sloppy work at Twitter - it's certainly not flattering for the profession.
The following graphic should reveal all. Note there's a problem with the link in the tweet:
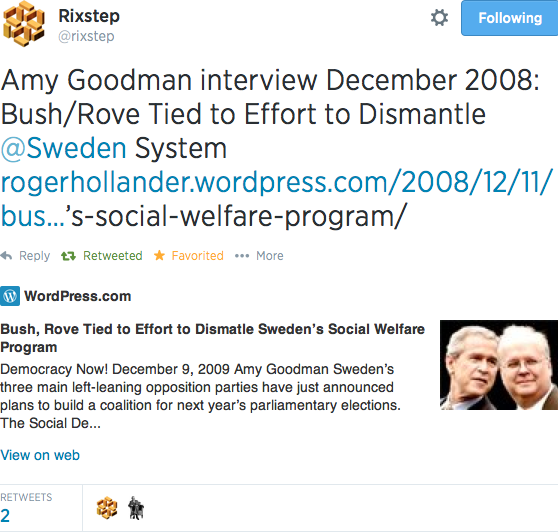
The problem is the curly apostrophe in the URL. That apostrophe is a really dumb character to use in a URL, but it's legitimate.
http://rogerhollander.wordpress.com/2008/12/11/bush-rove-tied-to-effort-to-dismatle-sweden’s-social-welfare-program/
What those geniuses in the Twitter UI crew are doing is setting sentinels for illegal URL characters, or rather they're gradually - at a snail's pace - expanding their set of legal characters, which of course is the head-up-arse way of going about it, but sadly the customary way of going about it at Twitter HQ.
They've previously had issues with myriad other characters - as many Twitter users have noticed - and only long after the fact discovered they're breaking URLs all over the place. And how do they go about correcting things? By assembling an array of real factual token delimiters? Oh no. That would be correct; it might require formal education in computer science; and therefore would absolutely not be the way to do things.
But now look below the vandalised link, for you'll see that underlying Twitter code was still able to fetch the link in question and embed a summary of the page. Which of course indicates there are two separate pieces of code at work there.
Another no-no.
This has also been seen before in the House of Twitter. Code that counts remaining characters out of the 140 was different on the ordinary and mobile sites - they had a discrepancy of one - and in addition, one of them counted characters before shrinking URLs, the other didn't. Meaning that on the one of the platforms, fully legit tweets way under the 140 mark were disallowed.
But this got even more comical, as they had yet another snippet of code counting the characters as you typed. So what appeared to be a legit tweet under the 140 limit was suddenly disallowed when you clicked, and you were met with the obnoxious admonition that you, and not them, should be more clever.
There has to be a limit, and the UI coders at Twitter have long since passed it.
Some people wonder - for real - why Ruby and other 'high level' languages are so bad. It's not that the languages are bad or that 'high level' always has to suck; it's that the pinheads pushed into those environments never get educated in how computer systems really work. Just drop the babes in their new toy land and let them play around. You're bound to get great things any day now.
Twitter management must do something radical. There are people who still remember 'Twitter 2.0' or 'NewTwitter' and all that 'golden ratio' codswallop. Someone might drag it to the surface again and tarnish the company reputation. There is no reason programmers doing the UI should be mental midgets - make sure they know what the others know (and know it well) before you let them enter the corral of UI delights.
|